传统上,NLP 是使用语言规则、字典、正则表达式和机器学习来执行特定任务的,例如自动分类或文本摘要。然而,近年来,深度学习技术已经占据了 NLP 领域的大部分领域。
深度学习利用了大规模数据集的可用性、廉价的计算以及在较少人工参与的情况下进行大规模学习的技术。使用transformer架构的预训练语言模型特别成功。
例如,BERT 是谷歌于 2018 年发布的一种预训练语言模型。从那时起,它就成为当今大多数现代 NLP 技术的灵感来源。Elastic Stack 机器学习功能围绕 BERT 和 Transformer 模型构建。
这些功能支持 BERT 的标记化方案(称为 WordPiece)和符合标准 BERT 模型接口的转换器模型。
Elastic发布了Elasticsearch Relevance Engine(Elasticsearch相关性引擎),该引擎通过多种方式,为用户提供提高相关性的能力,其中特别重要的一点,就是允许开发人员在 Elastic 中管理和使用自己的transformer模型。
为了合并 Transformer 模型并进行预测,Elasticsearch 使用了 libtorch,它是 PyTorch 的底层原生库。经过训练的模型必须采用 TorchScript 表示,才能与 Elastic Stack 机器学习功能一起使用。
因此,我们通常需要先将模型上传到Elasticsearch当中

有两种方法可以上传模型到ES:
- Eland通过脚本直接下载
- 下载到本地,再本地导入
然后,将其作为输入输出的网关,对数据进行额外处理:
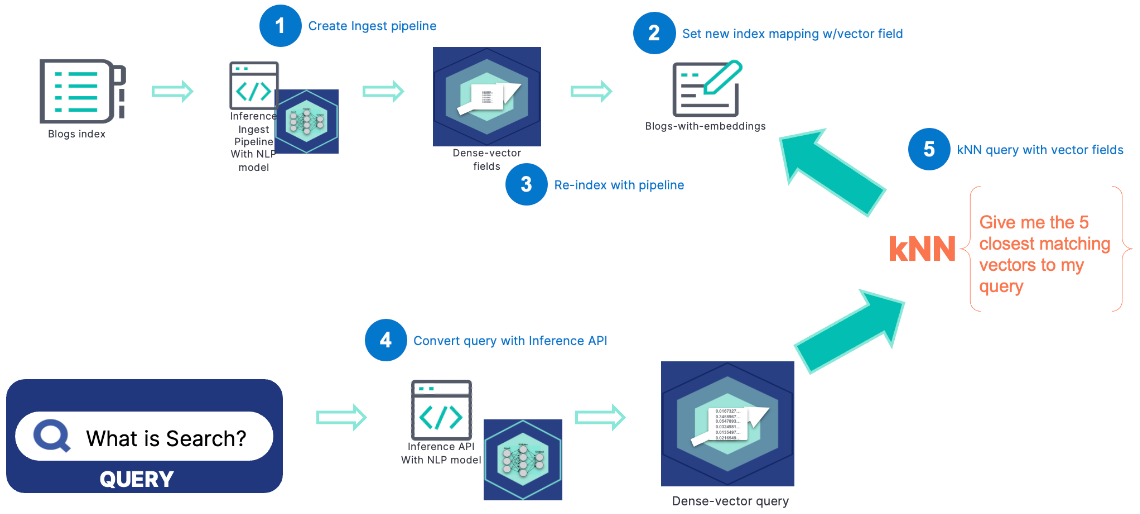
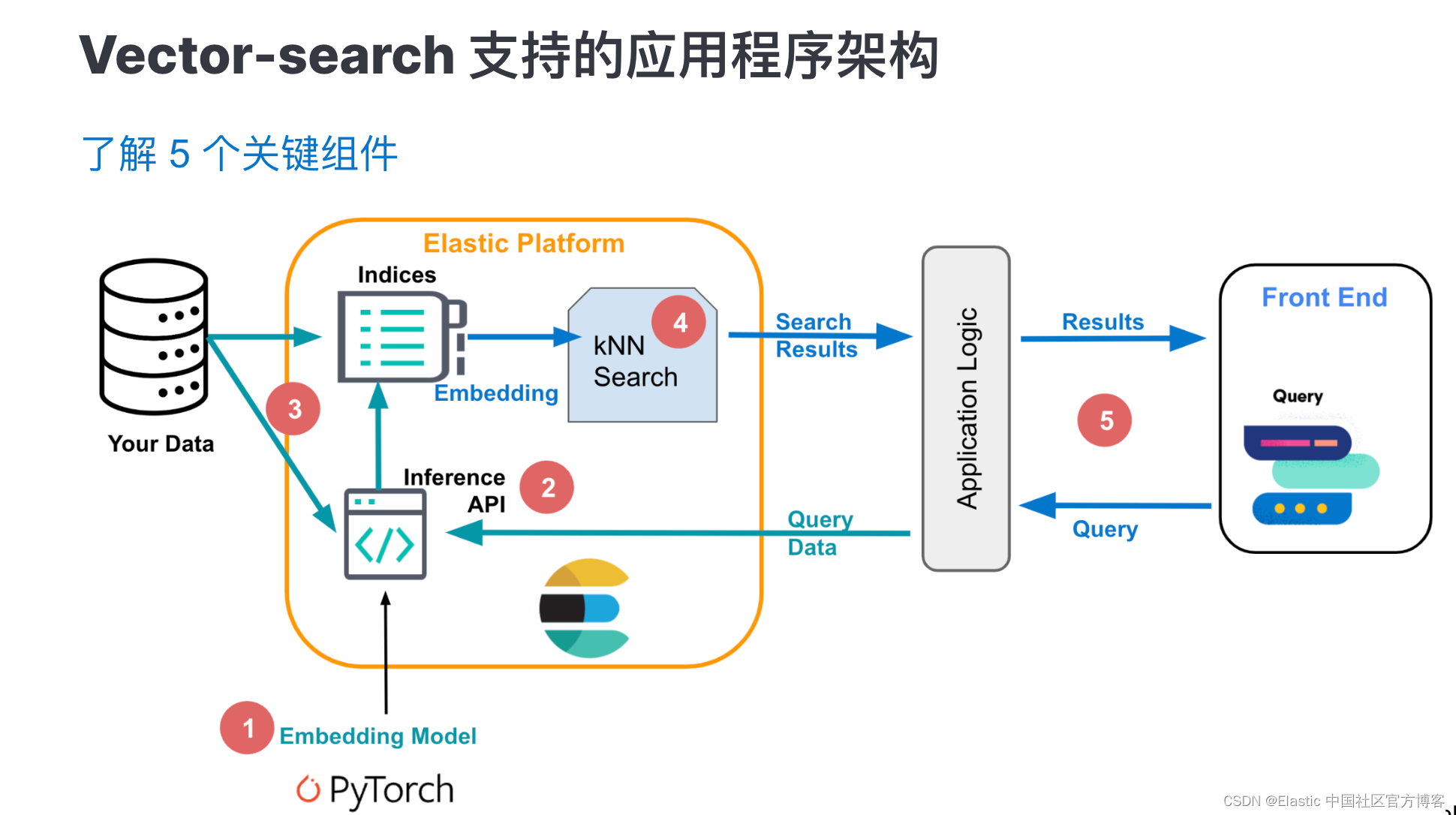
才能够让其与Elasticsearch的工作模式进行无缝结合。
我们可以通过Eland和 Kibana 提供的工具,快速完成以上步骤,具体步骤简单描述为:
关于机器学习与NLP的官方文档(8.11based)
关于Infer trained model deployment API
最后编辑:admin 更新时间:2024-07-04 11:58
