TesseractOcr 安装、使用、训练
1,安装
ocr下载地址:
https://digi.bib.uni-mannheim.de/tesseract/
安装过程中有一点要注意: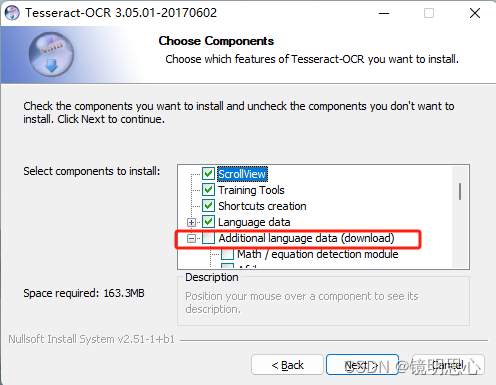
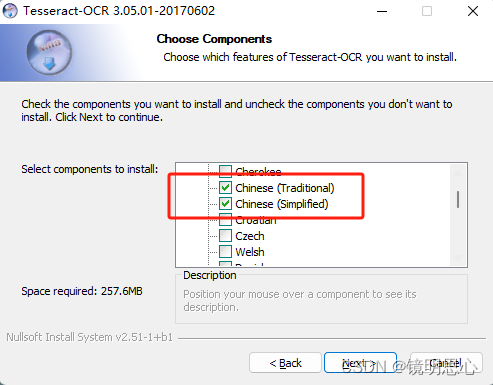
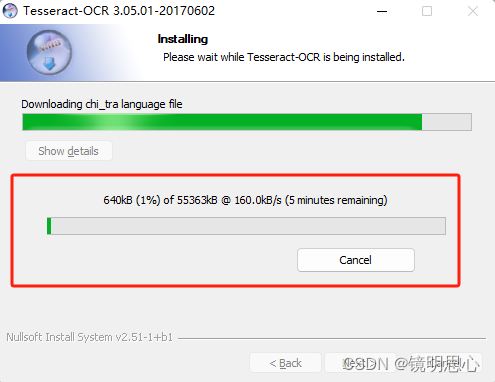
等待中文包下载完成即可安装成功。
查看安装信息:tesseract.exe -v
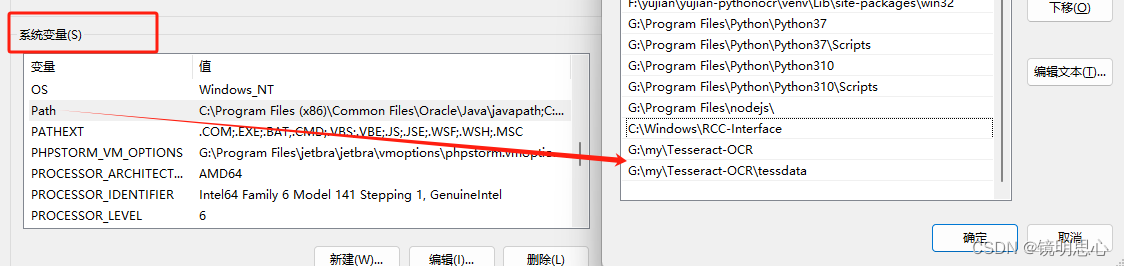
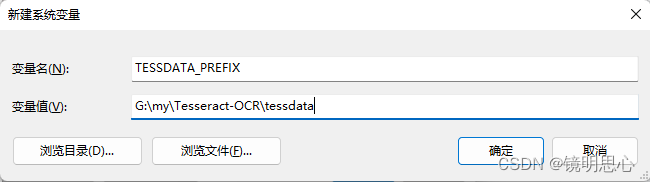
这是因为没有配置环境变量:在我的电脑——>右键属性——>高级系统设置——>环境变量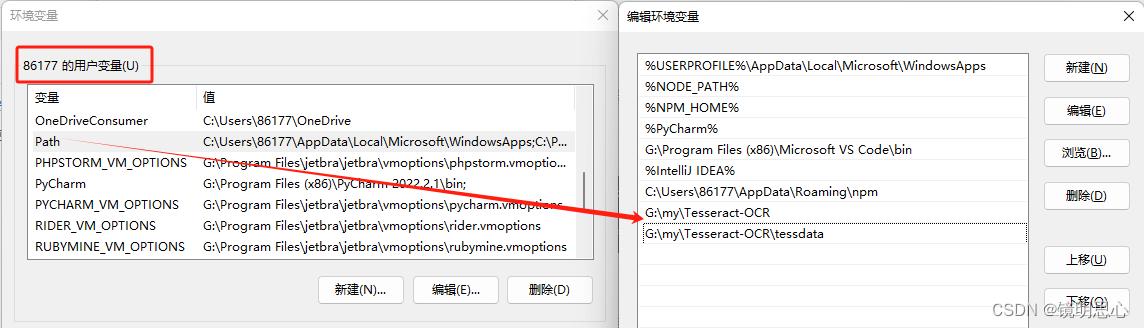
2,使用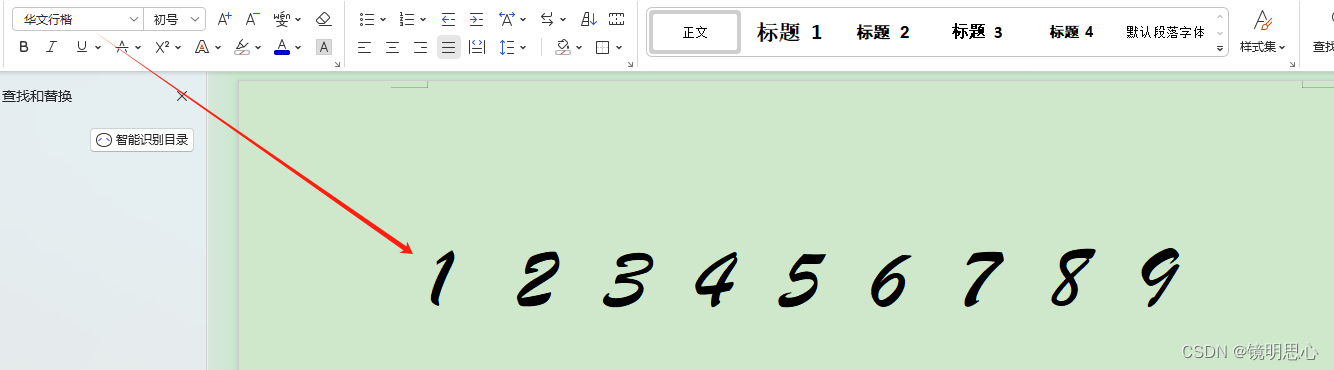
先使用华文行楷进行简单的测试一下准确性:截图保存png就好
直接在图片文件夹使用cmd打开黑窗口,使用命令:
tesseract test.png output_1 -l eng
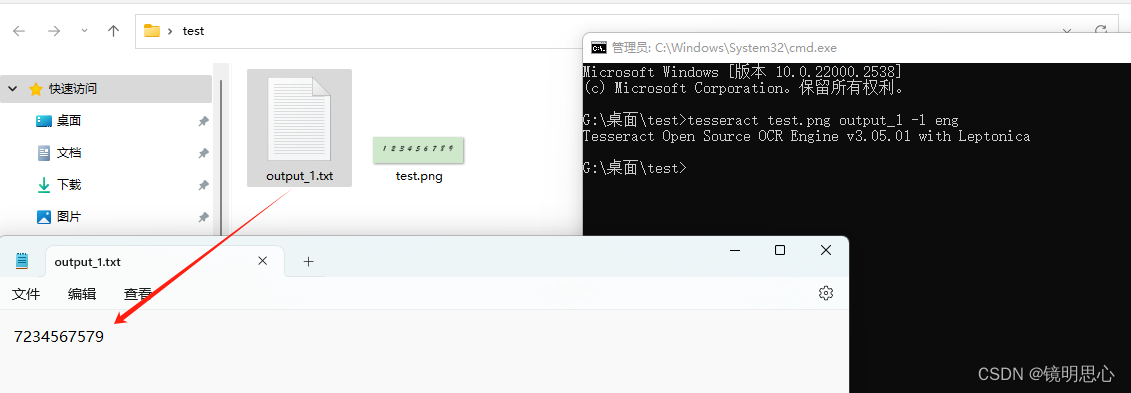
可以看到识别出来的准确性还是很差的,所以我们要训练!!!
3,训练
如果要训练自己的字库以提高准确性,需要用到 jTessBoxEditor
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/

就以我们刚刚使用的那个图为例
点击打开之后,会再出来一个弹窗
我们对其命名:num.font.exp0

可以看到,在原图片文件夹中新出来了一个tif图片文件
我们可以根据这个tif文件来生成box文件
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
切记:box文件名要和tif文件名保持一致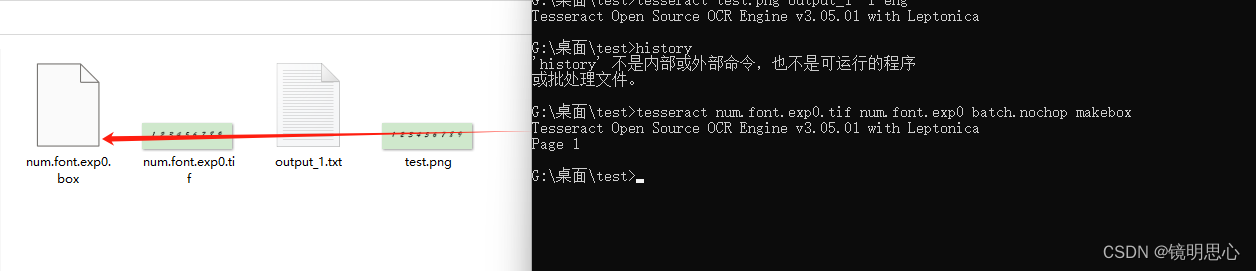
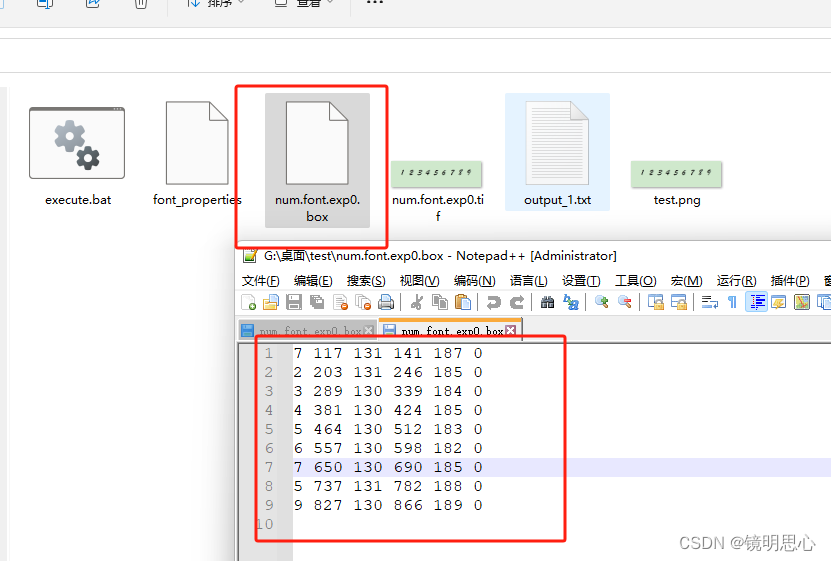
可以看到,生成的box文件里面对于图片的识别是不准确的,所以我们要训练它。

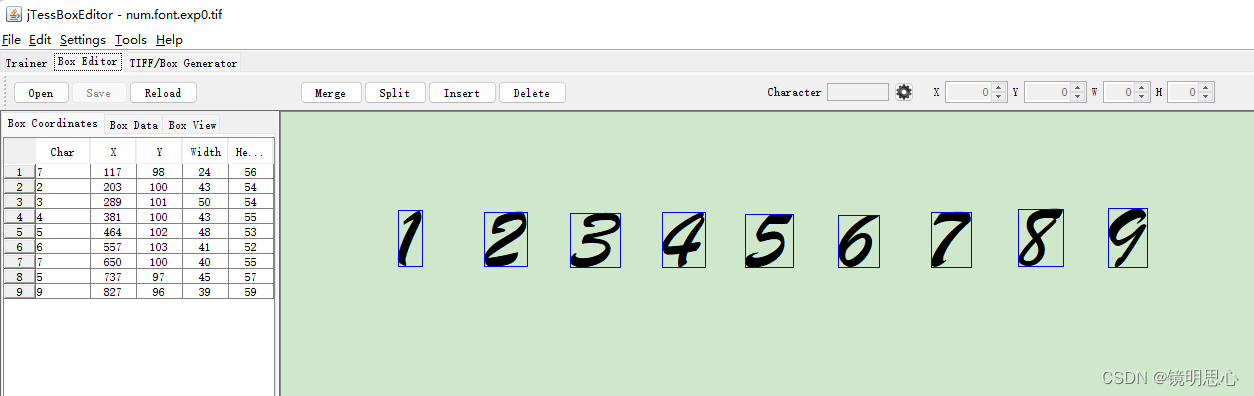
现在我们可以训练它了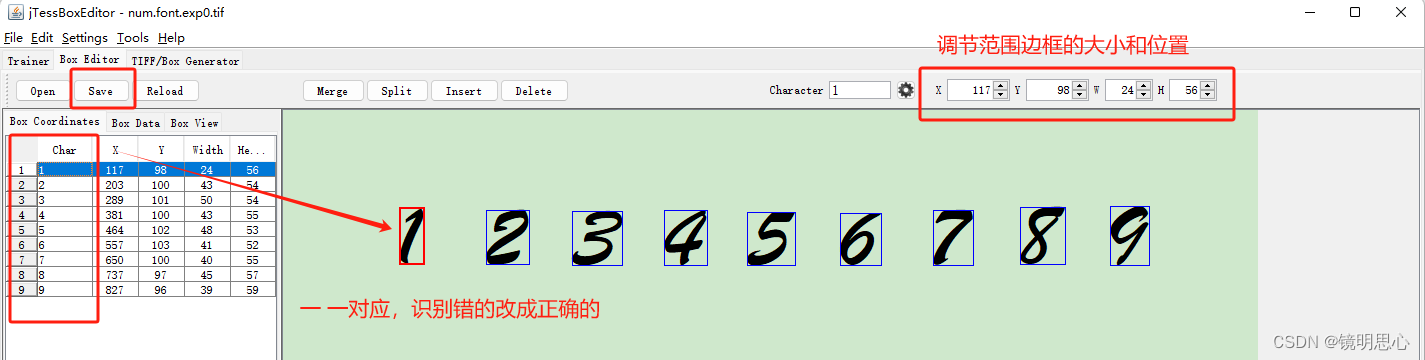
训练之后我们点击保存即可。
接下来就是生成训练过的最新字库了。
先在图片文件夹创建一个font_properties文件,内容为:font 0 0 0 0 0
然后在图片文件夹中创建执行文件:execute.bat
内容为:
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
此时可以看到我们的文件夹已经有了这几个文件: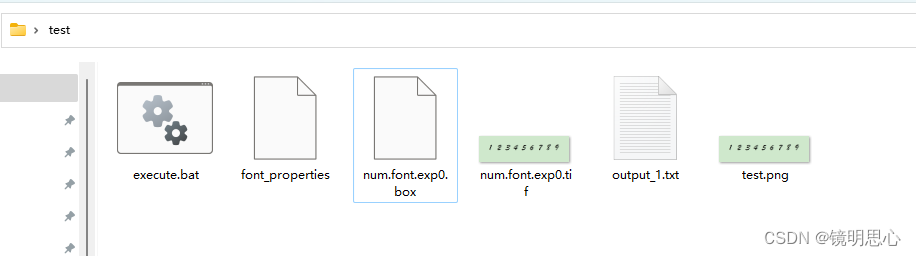
直接双击执行execute.bat文件即可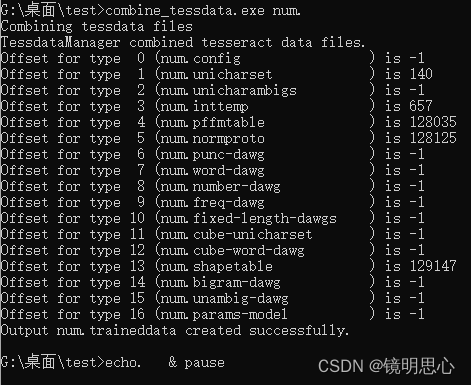
此时我们文件夹多了很多文件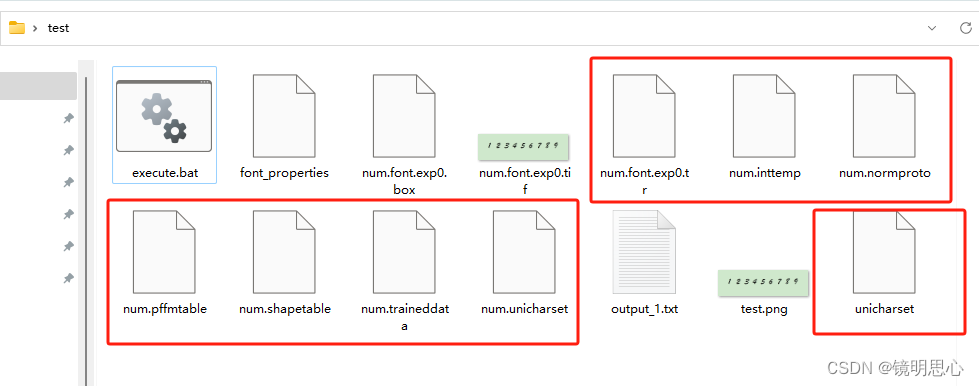
此时我们再打开num.font.exp0.box文件
可以看到里面的内容已经变成最新训练的正确的字体了
如果你打开发现里面的内容没有变化,还是之前的内容,不用担心,将execute.bat生成的文件全部删除,然后重新打开 jTessBoxEditor,然后重新训练保存,然后再双击execute.bat重新生成文件,再打开num.font.exp0.box文件,就可以了。
下面是把新的字库应用到识别中:
我们把num.traineddata复制到tesseract安装目录下tessdata下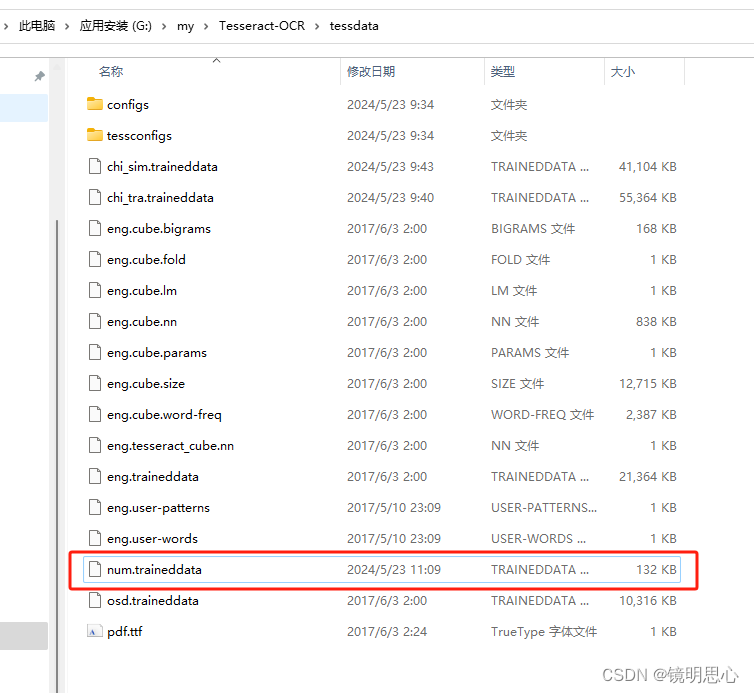
然后打开黑窗口进行重新识别
因为我们的文件名是num开头,所以命令要加上num,否则就是使用默认的字库了
tesseract test.png output_2 -l num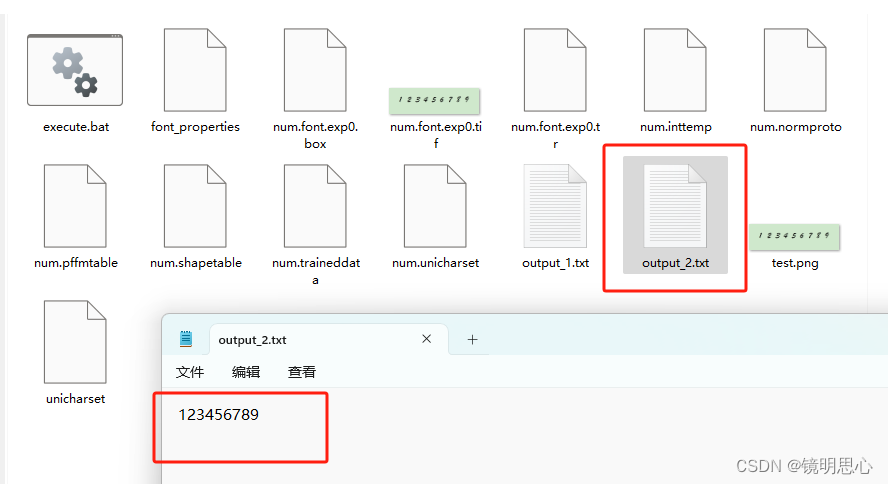
此时看到,经过训练后的字库,可以成功识别所有的数字,接下来我们再图片中再加一个0,看是否可以识别到。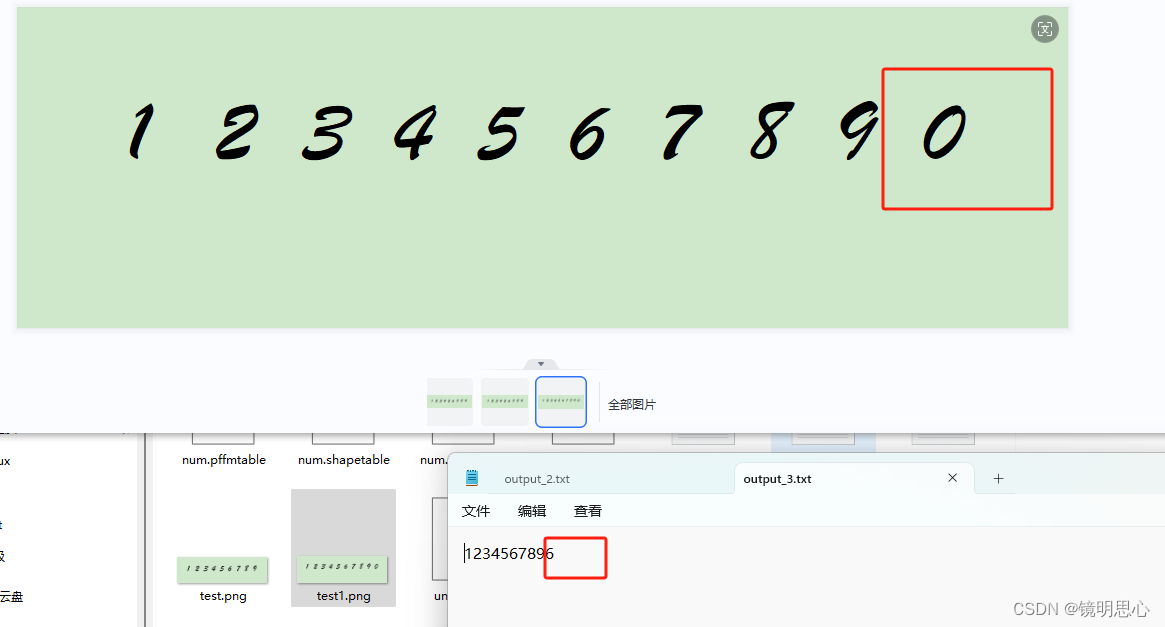
可以看到,tesseract OCR将0识别成了6,所以如果想要获得更精准的识别,还是要多训练字库。
tesseract OCR根据训练字库识别内容,依赖于字体,根据被识别的图片的字体,来针对性的进行训练,可以极大的提高识别的精准度。
最后编辑:admin 更新时间:2024-07-04 12:25
