作为我们自然语言处理 (NLP) 博客系列的一部分,我们将介绍一个使用文本嵌入模型生成文本内容的向量表示并演示对生成的向量进行向量相似性搜索的示例。我们将在 Elasticsearch 上部署一个公开可用的模型,并在摄取管道中使用它来从文本文档生成嵌入。然后,我们将展示如何在向量相似性搜索中使用这些嵌入(embedding)来查找给定查询的语义相似文档。
向量相似性搜索(vector similarity search),或者通常称为语义搜索,超越了传统的基于关键字的搜索,允许用户找到可能没有任何共同关键字的语义相似的文档,从而提供更广泛的结果。向量相似性搜索对密集向量进行操作,并使用 k-最近邻(k-nearest neighbour)搜索来查找相似向量。为此,首先需要使用文本嵌入模型将文本形式的内容转换为其数字向量表示。
我们将使用来自 MS MARCO Passage Ranking Task 的公共数据集进行演示。它由来自 Microsoft Bing 搜索引擎的真实问题和人工生成的答案组成。该数据集是测试向量相似性搜索的完美资源,首先,因为问答是向量搜索最常见的用例之一,其次,MS MARCO 排行榜中的顶级论文以某种形式使用了向量搜索。
在我们的示例中,我们将使用此数据集的样本,使用模型生成文本嵌入,然后对其运行向量搜索。我们还希望对向量搜索产生的结果的质量进行快速验证。在今天的展示中,我将使用 Elastic Stack 8.2 来进行展示。
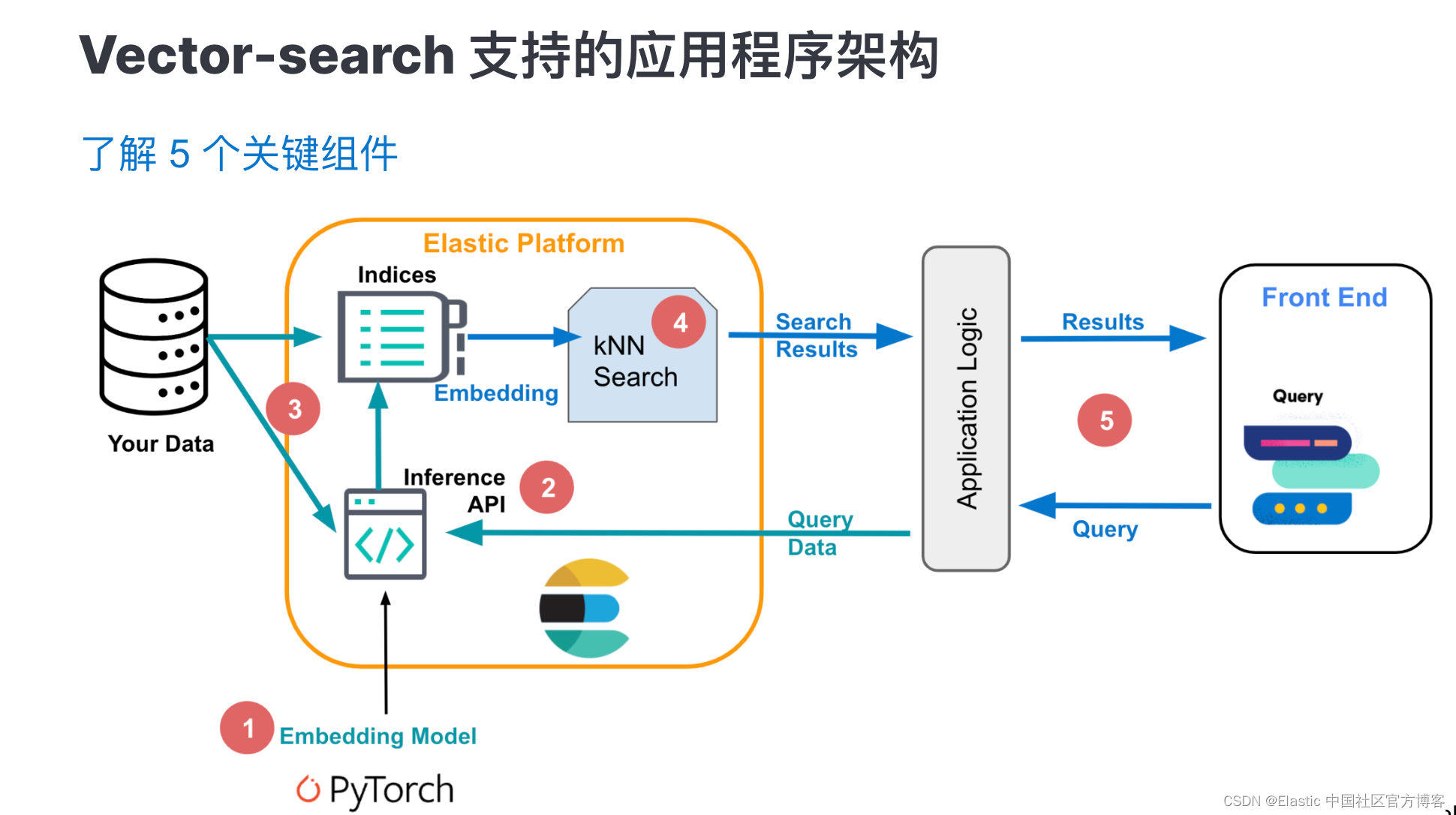
针对一个向量搜索来说,它的架构可以表述为如下:
装载模型
运行 eland_import_hub_model 脚本。 例如:
eland_import_hub_model --url <clusterUrl> \ --hub-model-id sentence-transformers/msmarco-distilbert-base-tas-b \ --task-type text_embedding
指定 URL 以访问你的集群。 例如,https://<user>:<password>@<hostname>:<port>。
在 Hugging Face 模型中心中指定模型的标识符。
指定 NLP 任务的类型。 支持的值为 fill_mask、ner、text_classification、text_embedding, question_answering 和 zero_shot_classification。
我们可以通过在 Kibana 控制台中使用这个示例来测试模型的成功部署:
POST /_ml/trained_models/sentence-transformers__msmarco-distilbert-base-tas-b/deployment/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}
装载初始数据
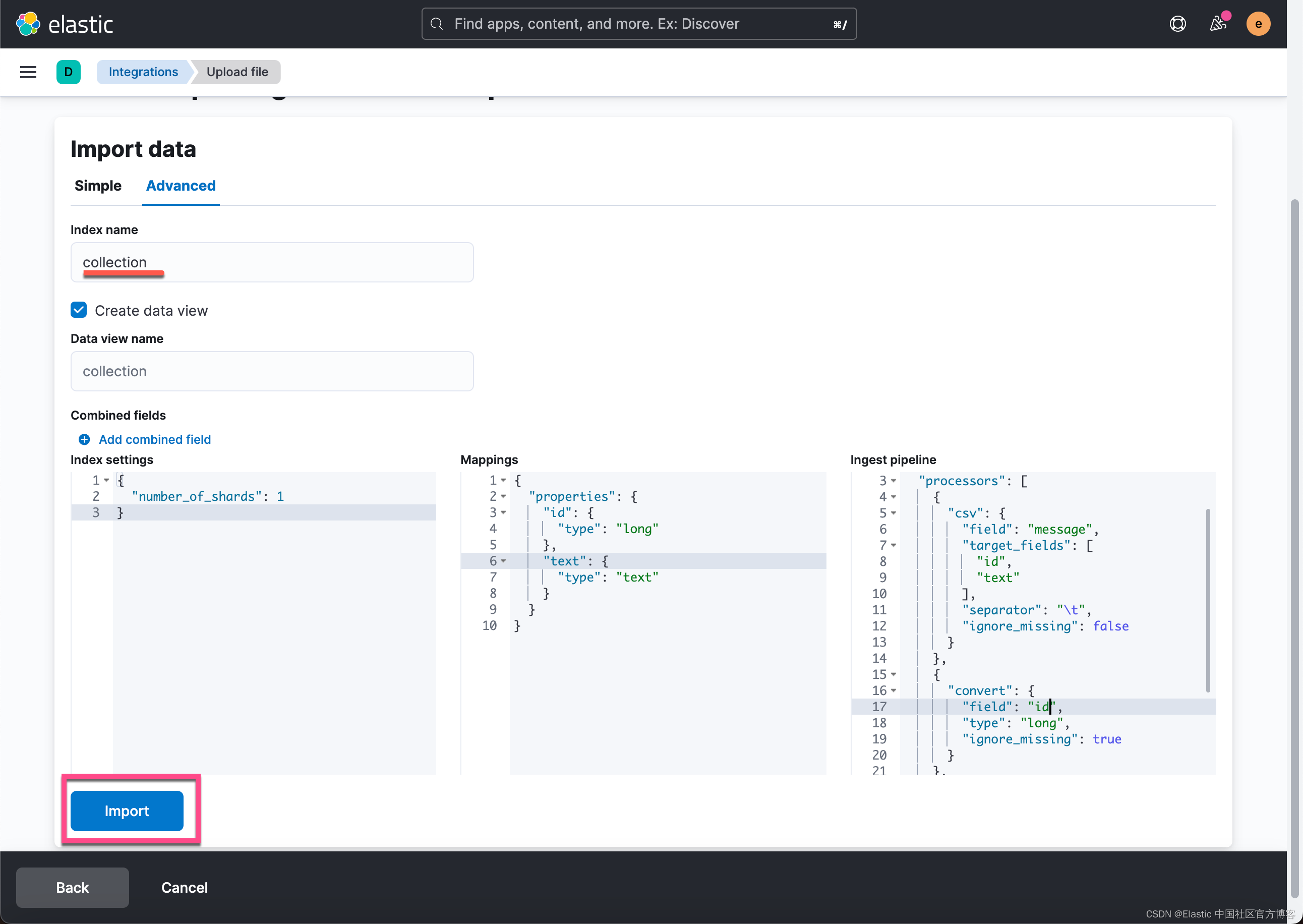
如介绍中所述,我们使用 MS MARCO Passage Ranking 数据集。 数据集非常大,包含超过 800 万个段落。 在我们的示例中,我们使用了它的一个子集,该子集在 2019 TREC Deep Learning Track 的测试阶段使用。 用于重新排序任务的数据集 msmarco-passagetest2019-top1000.tsv 包含 200 个查询,每个查询由一个简单的 IR 系统提取的相关文本段落列表。 从该数据集中,我们提取了所有带有 id 的唯一段落,并将它们放入一个单独的 tsv 文件中,总共 182469 个段落。 我们使用这个文件作为我们的数据集。
创建 pipeline
我们希望使用推理处理器(inference processor)处理初始数据,该处理器将为每个段落添加嵌入(embedding)。 为此,我们创建了一个文本嵌入摄取管道,然后使用该管道重新索引我们的初始数据。
在 Kibana 控制台中,我们创建了一个摄取管道用于文本嵌入,并将其称为 text-embedding。 这些段落位于名为 text 的字段中。 正如我们之前所做的,我们将定义一个 field_map 来将文本映射到模型期望的字段 text_field。 同样 on_failure 处理程序设置为将故障索引到不同的索引中:
PUT _ingest/pipeline/text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__msmarco-distilbert-base-tas-b",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Reindex
我们希望通过 text-embedding 管道推送文档,将文档从 collection 索引重新索引(reindex)到新的 collection-with-embedding 索引中,以便在 collection-with-embeddings 索引中的文档具有用于段落嵌入的附加字段。 但在我们这样做之前,我们需要为我们的目标索引创建和定义一个映射,特别是对于摄取处理器将存储嵌入的字段 text_embedding.predicted_value。 如果我们不这样做,嵌入将被索引到常规浮点 float 字段中,并且不能用于向量相似性搜索。 我们使用的模型将嵌入生成为 768 维向量,因此我们使用具有 768 个维度的索引 dense_vector 字段类型,如下所示:
PUT collection-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
},
"text": {
"type": "text"
}
}
}
}
最后,我们准备重新索引。 鉴于 reindex 需要一些时间来处理所有文档并对其进行推断,我们通过调用带有 wait_for_completion=false 标志的 API 在后台reindex:
POST _reindex?wait_for_completion=false
{
"source": {
"index": "collection"
},
"dest": {
"index": "collection-with-embeddings",
"pipeline": "text-embeddings"
}
}
以上返回一个任务 ID。 我们可以通过以下方式监控任务的进度:
GET _tasks/<task_id>
Vector Similarity Search
目前我们不支持在搜索请求期间从查询词隐式生成嵌入,因此我们的语义搜索被组织为一个两步过程:
从文本查询中获取文本嵌入。 为此,我们使用模型的 _infer API。
使用向量搜索来查找与查询文本语义相似的文档。 在 Elasticsearch v8.0 中,我们引入了一个新的 _knn_search 端点,它允许在索引的 dense_vector 字段上进行有效的近似最近邻搜索。 我们使用 _knn_search API 来查找最近的文档。
例如,给一个文本查询 “how is the weather in jamaica”,我们首先运行 _infer API 以得到一个密集向量的 embedding:
POST /_ml/trained_models/sentence-transformers__msmarco-distilbert-base-tas-b/deployment/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}
上面的命令返回如下的结果:
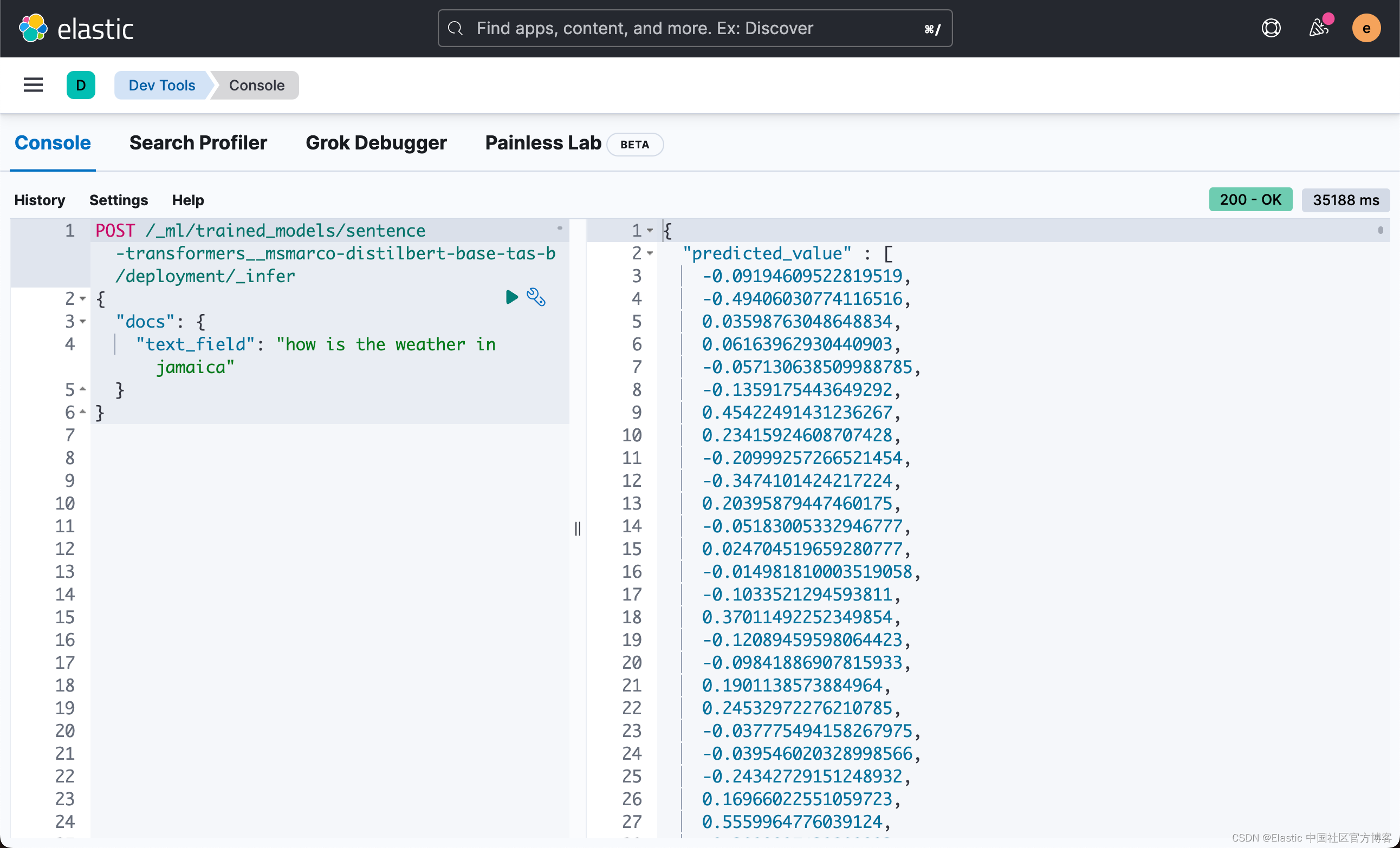
上面的 predicted_value 是一个768 维的向量。之后,我们将生成的密集向量(dense vector)插入到 _knn_search 中,如下所示:
GET collection-with-embeddings/_knn_search
{
"knn": {
"field": "text_embedding.predicted_value",
"query_vector": [
-0.09194609522819519,
-0.49406030774116516,
0.03598763048648834,
…
],
"k": 10,
"num_candidates": 100
},
"_source": [
"id",
"text"
]
}
结果,我们得到最接近查询文档的前 10 个文档,按它们与查询的接近程度排序:
"hits" : [
{
"_index" : "collection-with-embeddings",
"_id" : "6H_OsH8Bi5IvRzQ7g-Aa",
"_score" : 0.9527166,
"_source" : {
"id" : 6140,
"text" : "Ocho Rios Jamaica Weather - Winter ( December, January And February) The winters in this town are usually colder when compared to other parts of the island. The average temperature for December, January and February are 81 °F and 79 °F respectively. All three months usually have a high temperature of 84 °F."
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "6n_OsH8Bi5IvRzQ7g-Aa",
"_score" : 0.95225316,
"_source" : {
"id" : 6142,
"text" : "Jamaica Weather and When to Go. Jamaica weather essentials. For more details on the current temperature, wind, and stuff like that you can check any search engine weather feature. The rainy months, also called the rainy season, are generally from the end of April, or early May, until the end of September or early October."
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "5n_OsH8Bi5IvRzQ7g-Aa",
"_score" : 0.9394933,
"_source" : {
"id" : 6138,
"text" : "Quick Answer. Hurricane season in Jamaica starts on June 1 and ends on Nov. 30. Satellite weather forecasts work to allow tourists and island dwellers adequate time to take precautions when hurricanes approach during those months. Continue Reading."
}
},
语义搜索 - Semantic search
在上面的演示中,我们做一个搜索,需要如下的两个步骤:
通过 _infer API 接口获取搜索字符串的向量
通过 _knn_search 端点来对上一步获得的向量进行搜索
幸运的是,在最新的 8.7 的版本中,我们可以通过一个命令把上面的两个步骤合二为一:
GET collection-with-embeddings/_search
{
"knn": {
"field": "text_embedding.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__msmarco-distilbert-base-tas-b",
"model_text": "How is the weather in Jamaica?"
}
},
"k": 10,
"num_candidates": 100
},
"_source": [
"id",
"text"
]
}
因此,你会从 collection-with-embedings 索引中收到与查询含义最接近的前 10 个文档,这些文档按与查询的接近程度排序:
"hits" : [
{
"_index" : "collection-with-embeddings",
"_id" : "47TPtn8BjSkJO8zzKq_o",
"_score" : 0.94591534,
"_source" : {
"id" : 434125,
"text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading."
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "3LTPtn8BjSkJO8zzKJO1",
"_score" : 0.94536424,
"_source" : {
"id" : 4498474,
"text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year"
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "KrXPtn8BjSkJO8zzPbDW",
"_score" : 0.9432083,
"_source" : {
"id" : 190804,
"text" : "Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading"
}
},
(...)
]
最后编辑:admin 更新时间:2024-07-01 18:08
