在本文中,我们将主要展示,如何将一个中文的NER模型部署到elasticsearch集群当中
Elastic机器学习模块对NER模型的限制
目前,Elastic Stack支持对以下 NLP 操作:
而NER(命名实体识别)属于信息提取这一分类,填充蒙版与问答也属于这一范畴。
命名实体识别 (NER) 任务可以识别和分类非结构化文本中的某些实体(通常是专有名词)。命名实体通常是指现实世界中的对象,例如人(PERSON)、位置(LOC)、组织(ORG)和其他(MISC)由专有名称一致引用的杂项实体。
NER 是识别关键信息、添加结构和深入了解您的内容的有用工具。它在处理和探索大量文本(如新闻文章、维基页面或网站)时特别有用。它可以更容易地理解文本的主题并将相似的内容组合在一起。
因此,对于一个搜索引擎来说,NER是深度查询理解(Deep Query Understanding,简称 DQU)的底层基础信号,能应用于搜索召回、用户意图识别、实体链接、图探索等环节,NER信号的质量,直接影响到用户的搜索体验。
但很不幸的是,目前Elasticsearch仅仅兼容测试了以下几种英文的模型:
- BERT base NER
- DistilBERT base cased finetuned conll03 English
- DistilRoBERTa base NER conll2003
- DistilBERT base uncased finetuned conll03 English
并且,在目前版本,只支持以IOB(Begin, Inside, Outside)形式打标签的模型。因此,如果我们在Huggingface上选择了一个中文的NER模型,比如这个:https://huggingface.co/uer/roberta-base-finetuned-cluener2020-chinese/
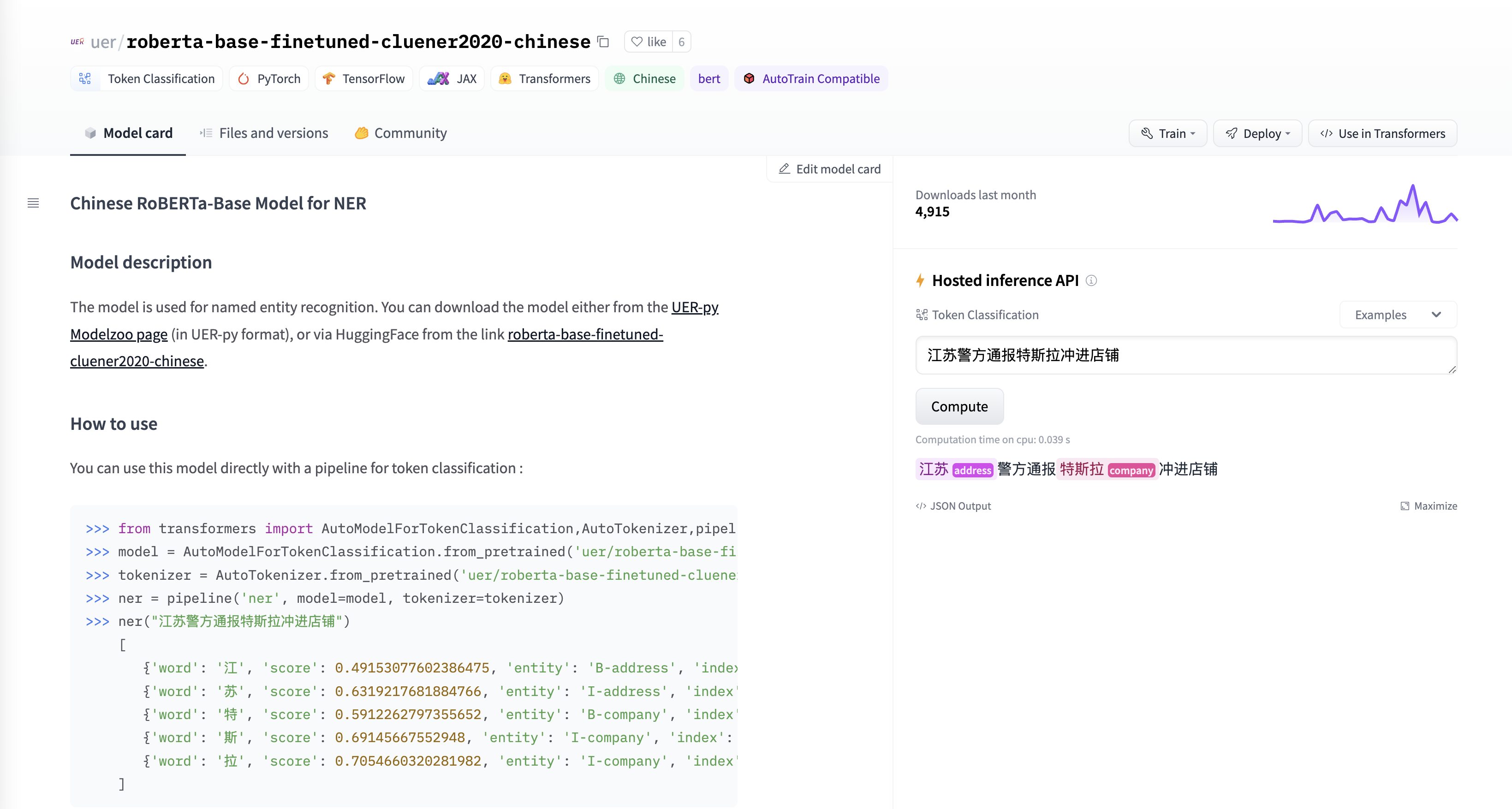
然后部署到Elasticsearch集群:
docker run -it --rm --network host elastic/eland eland_import_hub_model \
--url http://localhost:9200 -u elastic -p yourpassword \
--hub-model-id uer/roberta-base-finetuned-cluener2020-chinese --task-type ner
会有如下提示:
2022-08-05 02:54:41,792 INFO : Establishing connection to Elasticsearch
2022-08-05 02:54:41,882 INFO : Connected to cluster named 'docker-cluster' (version: 8.4.0-SNAPSHOT)
2022-08-05 02:54:41,883 INFO : Loading HuggingFace transformer tokenizer and model 'uer/roberta-base-finetuned-cluener2020-chinese'
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 295/295 [00:00<00:00, 280kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.76k/1.76k [00:00<00:00, 3.02MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 107k/107k [00:01<00:00, 74.2kB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 112/112 [00:00<00:00, 132kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 388M/388M [19:02<00:00, 356kB/s]
Asking to pad to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no padding.
2022-08-05 03:14:18,830 INFO : Creating model with id 'uer__roberta-base-finetuned-cluener2020-chinese'
Traceback (most recent call last):
File "/usr/local/bin/eland_import_hub_model", line 219, in <module>
ptm.put_config(config=config)
File "/usr/local/lib/python3.9/dist-packages/eland/ml/pytorch/_pytorch_model.py", line 78, in put_config
self._client.ml.put_trained_model(model_id=self.model_id, **config_map)
File "/usr/local/lib/python3.9/dist-packages/elasticsearch/_sync/client/utils.py", line 414, in wrapped
return api(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/elasticsearch/_sync/client/ml.py", line 3258, in put_trained_model
return self.perform_request( # type: ignore[return-value]
File "/usr/local/lib/python3.9/dist-packages/elasticsearch/_sync/client/_base.py", line 390, in perform_request
return self._client.perform_request(
File "/usr/local/lib/python3.9/dist-packages/elasticsearch/_sync/client/_base.py", line 321, in perform_request
raise HTTP_EXCEPTIONS.get(meta.status, ApiError)(
elasticsearch.BadRequestError: BadRequestError(400, 'x_content_parse_exception', '[ner] only allows IOB tokenization tagging for classification labels; provided [S_address, S_book, S_company, S_game, S_government, S_movie, S_name, S_organization, S_position, S_scene, [PAD]]')
部署中文模型的解决方案
为了解决以上问题,我们需要对模型做一些修改,使其符合当前Elasticsearch的限制。
也就是说,我们需要将目前模型的打标方式,改成elasticsearch兼容的模式:
{
"architectures": [
"BertForTokenClassification"
],
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "O",
"1": "B-address",
"2": "I-address",
"3": "B-book",
"4": "I-book",
"5": "B-company",
"6": "I-company",
"7": "B-game",
"8": "I-game",
"9": "B-government",
"10": "I-government",
"11": "B-movie",
"12": "I-movie",
"13": "B-name",
"14": "I-name",
"15": "B-organization",
"16": "I-organization",
"17": "B-position",
"18": "I-position",
"19": "B-scene",
"20": "I-scene",
"21": "S-address",
"22": "S-book",
"23": "S-company",
"24": "S-game",
"25": "S-government",
"26": "S-movie",
"27": "S-name",
"28": "S-organization",
"29": "S-position",
"30": "S-scene",
"31": "[PAD]"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"label2id": {
"B-address": 1,
"B-book": 3,
"B-company": 5,
"B-game": 7,
"B-government": 9,
"B-movie": 11,
"B-name": 13,
"B-organization": 15,
"B-position": 17,
"B-scene": 19,
"I-address": 2,
"I-book": 4,
"I-company": 6,
"I-game": 8,
"I-government": 10,
"I-movie": 12,
"I-name": 14,
"I-organization": 16,
"I-position": 18,
"I-scene": 20,
"O": 0,
"S-address": 21,
"S-book": 22,
"S-company": 23,
"S-game": 24,
"S-government": 25,
"S-movie": 26,
"S-name": 27,
"S-organization": 28,
"S-position": 29,
"S-scene": 30,
"[PAD]": 31
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"vocab_size": 21128
}
问题是我们是直接从Huggingface将模型导入到elasticsearch的,我们如何能够对别人的模型进行修改?
很简单,参考我的上一篇博文:在Huggingface上fork repository
我们可以把模型转移到自己的仓库中,然后可自行修改配置文件。在下图中:
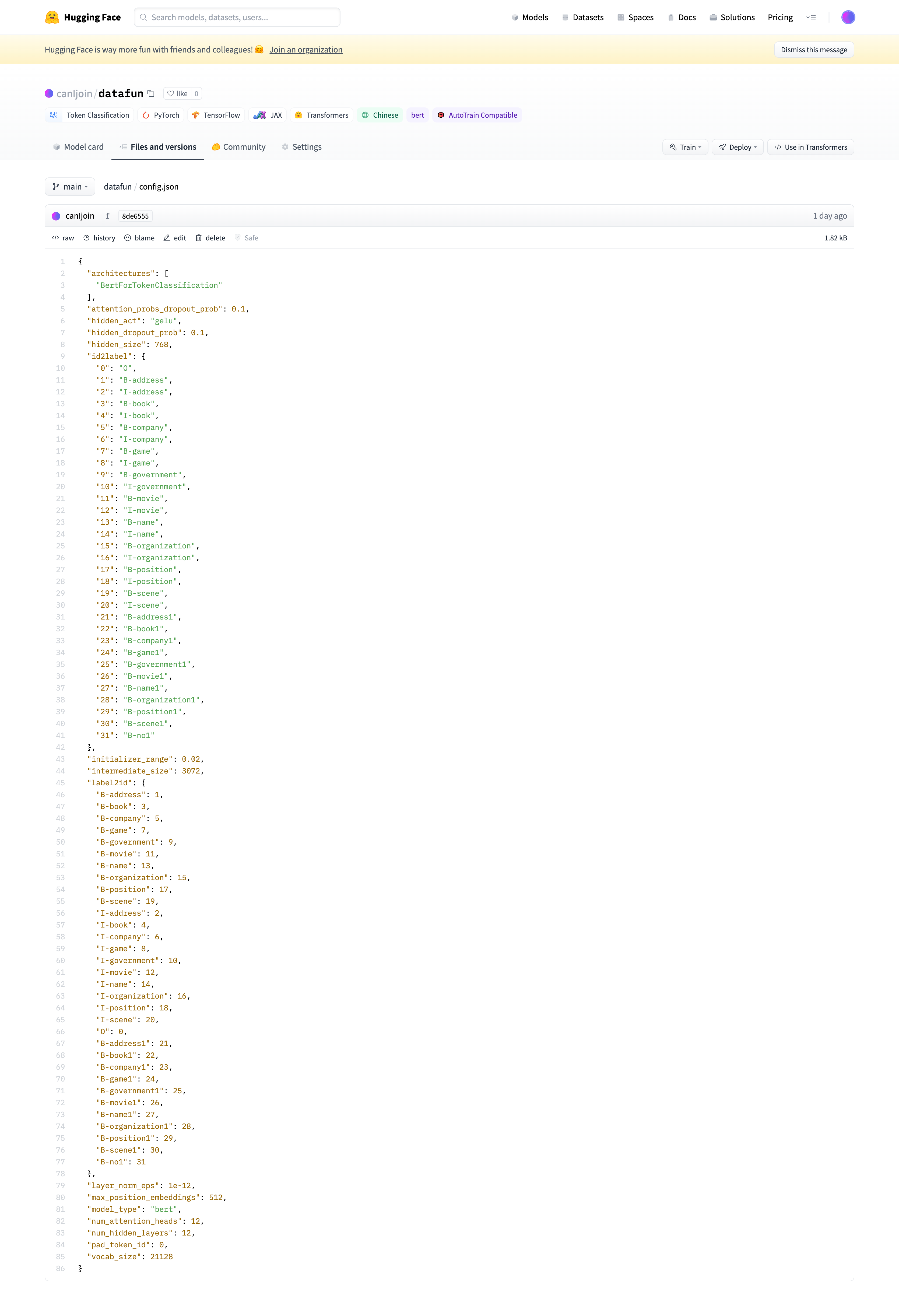
我们将模型搬移到自己的仓库,然后在线将congfig.json修改为符合IOB的模式。这里的修改包括:
S-address等标签改为B-address1[PAD]标签改为B-no
然后通过自己的仓库进行重新部署:
docker run -it --rm --network host elastic/eland eland_import_hub_model \
--url http://localhost:9200 -u elastic -p yourpassword \
--hub-model-id canIjoin/datafun --task-type ner
复制
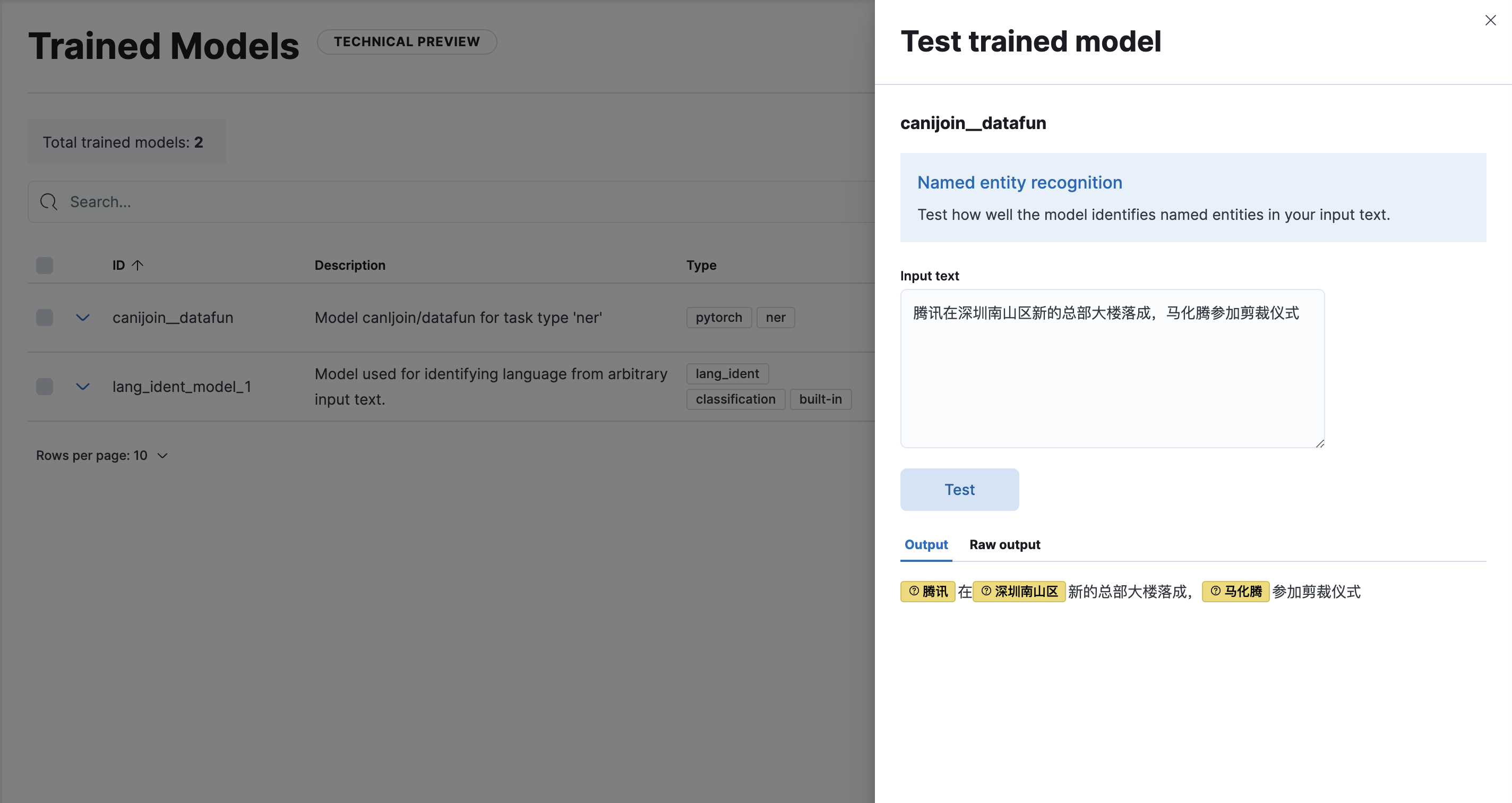
部署后,即可在界面上进行测试:
总结
本文中,我们介绍了在Elasticsearch中NLP的工作愿意,以及在集群中部署中文NER模型的一些限制与解决的办法。
而当下,像搜索深度理解,智能推荐等需要更为精准的搜索的场景,和NLP的结合已经成为必然。而在Elasticsearch中直接实现NLP,将帮助我们以极简的架构、极低的成本,极快的速度去上线一个包含了NLP功能的搜索项目
最后编辑:admin 更新时间:2024-07-01 18:08
